AdaCore Release Notes¶
GNAT Pro 25 Release Notes¶
We present here a few highlights of the new features in GNAT Pro 25. You can access the complete list in the GNAT Pro 25 feature file.
GCC back-end update¶
The GNAT Pro Ada, C and C++ has now been updated to GCC 13. See the GCC 13 changes for the corresponding capabilities as well as updates to C and C++.
Platforms¶
Platform status changes¶
Hosts¶
GNAT Pro now supports Linux ARM 64-bit native platforms
GNAT Pro for Ada for Windows native platforms now supports the LLVM back-end
Targets¶
GNAT Pro now supports bare-metal Morello platforms
GNAT Pro for Ada for ARM 64-bit cross linux platforms now supports the LLVM back-end
GNAT Pro for Ada for ARM 64-bit bare-metal platforms now supports the LLVM back-end
GNAT Pro for VxWorks 6 and 7 for PowerPC e500v2 are baselined
GNAT Pro for PowerPC 55xx and e500v2 bare-metal is baselined
Ada support¶
String interpolation¶
A new syntax allows variables or expressions to be used directly within string literals, such that the value of the variable or the expression is “interpolated” directly into the value of the enclosing string upon use at run-time.
Local declarations¶
Local variables or constants can now be declared at the place of any statement, not necessarily within a declarative part.
Support for target names in dimensionality analysis¶
Target names, introduced in Ada 2022 using the ‘@’ symbol, can now be used in conjunction with dimensionality analysis.
New External_Initialization extension¶
A new GNAT-specific extension has been added to the compiler to make it possible to embed binary resources stored in arbitrary files into executables.
New object attribute ‘Super¶
The compiler now recognizes a new attribute Super under the -gnatX0 switch (for experimental features), which can be applied to objects of tagged types in order to obtain a view conversion to the most immediate specific parent type. This can be useful for making nondispatching calls to a parent type’s primitive subprogram.
First_Controlling_Parameter aspect¶
A new pragma/aspect, First_Controlling_Parameter, has been added to the curated subset of language extensions for tagged types. This aspect modifies the semantics of controlling parameters. When a tagged type is marked with this aspect, only subprograms where the first parameter is of that type are treated as being dispatching primitives.
Symbolic backtraces¶
Support for symbolic backtraces with DLLs on Windows¶
Symbolic backtraces generated by means of the -Es binder switch now work in the presence of DLLs on Windows.
Print the load address in symbolic backtraces¶
The load address of PIE executables is now printed in symbolic backtraces too (it was already printed in nonsymbolic ones).
LLVM new capabilities¶
The llvm-gcc binary can now compile LLVM IR¶
LLVM IR in text or binary form (i.e., .ll or .bc files) can now be compiled with “llvm-gcc -c”.
Windows enhancements¶
Improved support for task priorities on Win32¶
The compiler now provides a more distributed mapping (covering a wider range) of task priorities on Win32 when pragma Task_Dispatching_Policy (FIFO_Within_Priorities) is not present. Additionally, documentation on the subject has been supplemented.
Libraries for VxWorks¶
Ada bindings to ARINC 653 P1-5 for Helix¶
GNAT for VxWorks7r2 Cert provides bindings to version 5 of ARINC 653 part 1, to be used with Helix Virtualization Platform.
GNATcoll-minimal for vx7r2 kernel modules¶
GNATcoll-minimal is now provided pre-compiled for vxWorks kernel modules. This allows use of the packages provided with GNATcoll-minimal without having to manually build GNATcoll-minimal for this target.
Optimizations¶
Elided temporary for aliased unconstrained array¶
The compiler no longer creates a temporary for the declaration of an aliased array with unconstrained nominal subtype that is initialized by a call to a function whose result subtype is also unconstrained.
Faster return for indefinite record with size clause¶
Functions whose result type is an indefinite record type, that is to say a discriminated record type with nondefaulted discriminants, no longer return on the secondary stack if the record type is declared with a size or object size clause that is accepted by the compiler.
Better Length attribute overflow-check elimination¶
The non-Strict overflow-checking code now does a better job of eliminating overflow checks when given an expression consisting only of predefined operators (including relationals), literals, identifiers, and conditional expressions. If it is both feasible and useful, the compiler rewrites a Length attribute reference as such an expression. “Feasible” means “the index type is the same type as the attribute reference type, so we can rewrite without using type conversions”. “Useful” means “Overflow_Mode is something other than Strict, so there is value in making overflow-check elimination easier”.
More compact debug information for packed fields¶
When fields of packed records were explicitly sized so as to use a biased representation, every such field would get a type of its own in debug information, in addition to the unpacked type. The redundancy has been eliminated, so that the fields share a single type.
Less duplication of Put_Image and Streaming routines¶
For untagged types, the implicitly declared subprograms needed to implement streaming attributes and the Ada-2022 Put_Image attribute were generated “on demand” prior to this enhancement, instead of when a given type is declared. This could result in code duplication when multiple functionally equivalent routines are generated. With this enhancement, we see more sharing (and consequently less duplication) of routines within the context of a single compilation unit.
Elimination of redundant validity checks¶
In some cases with validity checking enabled via the -gnatVa option, the compiler generated validity checks that can obviously never fail. These included validity checks for (some) static expressions, and consecutive identical checks generated for a single read of an object. Such redundant checks are no longer generated.
Improved size allocation for container aggregates¶
The initial capacity of containers that are initialized with container aggregates that iterate over a one-dimensional array object is now set to the size of the array instead of the default container capacity.
More efficient elaboration of local tagged types¶
The object code generated for the elaloration of tagged types that are not declared at library level is now more efficient.
Removal of global lock for controlled allocation¶
The implementation no longer uses a global lock during the dynamic allocation of controlled objects.
More efficient aggregates in conditional expressions¶
The object code generated for nonstatic aggregates that are dependent expressions of conditional expressions is now more efficient.
Stack usage for small dynamic string concatenations¶
The code generated by the compiler for small dynamic string concatenations now uses static stack allocation in more cases.
More efficient ordering operators for arrays of byte¶
The predefined ordering operators specified for discrete array types by RM 4.5.2(26/3) are now implemented more efficiently when their component type is a byte (unsigned), which is the case for type String.
Enhanced modulo reduction for nonbinary modular type¶
Modulo reduction for modular types whose modulus is not a power of two, both implicit or explicit by means of the ‘Mod attribute, is now implemented by an improved division-free algorithm at every optimization level except for -Os, and also without branches if the restriction No_Implicit_Conditionals is in effect.
Better support for packed types in Address Sanitizer¶
The support for Ada packed array types and packed record types has been improved in the Address Sanitizer, resulting in fewer false positives when it is enabled.
Improvement of memcpy generation¶
Calls to memcpy are no longer generated in the case where the target and destination addresses match.
GNAT Dynamic Analysis Suite 25 Release Notes¶
We present here a few highlights of the new features in GNAT DAS 25. You can access the complete list in the GNAT DAS 25 feature file.
Code coverage reports¶
UX for MCDC improved in gnatcov’s HTML report¶
Clicking on an MC/DC violation message in the HTML report highlights the source-code excerpt of the condition.
Function and call coverage for Ada in GNATcoverage¶
GNATcoverage is now able to provide coverage analysis of subprograms and calls for Ada. A call is considered covered when it has been executed at least once. A subprogram is covered if it has been entered at least once. This new coverage level can be activated alongside any preexisting coverage level combination, through the use of the “fun_call” option of the “–level” switch. See section 1.5.8 of the GNAT DAS user manual for more details.
Support for restricted runtimes¶
Widen support for trace file dump in GNATcoverage¶
GNATcoverage now supports dumping coverage traces to a file on a broader range of Ada runtimes. While previously dumping traces to file also required the Ada runtime to provide a GNAT.OS_Lib unit, the only requirements now are that the runtime must provide a Ada.Text_IO unit, with capability to write to files, and that the C standard library must be available for the target.
Tool integrations¶
Revamped GNATtest/GNATcov integration Makefile¶
The Makefile generated by GNATtest for assessing the level of coverage of the generated test harness has been enhanced to offer more flexibility in cross-compilation configurations. Instead of directly attempting to invoke GNATemulator, a shell script is generated for running the test driver executables. This shell script can be modified by the user and will not be regenerated after the first creation. Additionally, intermediate build targets have been added to allow only the instrumentation and build of the test drivers, leaving the execution and consolidation up to the user in the case where the shell script is not appropriate.
Support for the CCG compiler in GNATcoverage¶
GNATcoverage now supports instrumentation of projects that will be compiled with the CCG compiler. Due to limitations of the CCG runtime, there are some adjustments to the overall coverage workflow compared to a regular cross-compilation scenario, which are outlined in section 1.3.10 of the GNATdas user manual.
GNATfuzz integration with GNATtest¶
GNATfuzz and GNATtest can now share test inputs via a common test case format in JSON. This allows GNATfuzz to utilize a GNATtest Unit test campaign to generate a starting corpus, and GNATtest can benefit from a GNATfuzz campaign to increase code coverage.
Support for preprocessing¶
GNATfuzz support for preprocessing¶
When analyzing the user project under test, GNATfuzz now preprocesses the sources according to the -gnatep and -gnateD switches defined in the project file.
Support for Ada preprocessing in GNATcoverage¶
GNATcoverage now correctly handles preprocessing directives when instrumenting Ada source code. Instrumentation used to ignore or misplace them.
Selective coverage analysis¶
Support for disabling coverage analysis¶
GNATcoverage now supports disabling coverage analysis by means of pragmas (for Ada) or comment markers (for C/C++) when using source instrumentation. This disables the emission of SCOs, and the instrumentation for the designated region.
Support for block instrumentation¶
GNATcoverage now supports instrumenting block sequences as a whole, with the –instrument-block instrument switch. The source-coverage obligations do not change in this case, only the way they are discharged. If the last statement of the sequence is covered, all the statements of the sequence are marked as covered as well.
Out-of-source annotation support in GNATcoverage¶
GNATcoverage now has a mechanism to generate companion files to describe annotations concerning the instrumentation process and coverage analysis. This mechanism supports the same set of annotations that can be added to source files with pragma Annotate. This feature may be particularly useful for users who do not have the possibility of modifying their source files as part of coverage-analysis activities. The annotation files can be created and augmented using the new gnatcov add-annotation command. See section 1.9 of the GNATdas user manual for more details.
Handling coverage buffers¶
New coverage-buffer reset API in GNATcoverage¶
GNATcoverage now provides an API to specify locations, in the sources, where coverage buffers will be cleared. This can be used to isolate coverage results for multiple executions of a given subprogram without needing to resort to multiple test-driver executions, to avoid incidental coverage between tests, or between setup code and test execution. The buffer reset indications take the form of Annotate pragmas in Ada code, and of specially formatted comments in C or C++ code. See the user manual for further details.
Optionally specify files with manual dump trigger¶
When using –dump-trigger=manual, the user can now specify the files containing the dump indications with “–dump-trigger=manual,<list_of_files>”, where list_of_files is either a comma-separated list of files or a response file. This speeds up the dump indication replacement by preventing the need to scan the entire source base in search of dump insertion points.
Test case generation from structural data¶
GNATtest can now automatically generate values as input to test cases based on the structure of subprogram parameters.
GNATfuzz enhancements¶
Add initial support for private types¶
GNATfuzz now supports fuzzing Ada private types. For example:
package Test is
type P_Type is private;
procedure Foo (P : in out P_Type);
private
type I_Type is range 0 .. 1;
type P_Type is array (I_Type, I_Type) of Boolean;
end Test;
Add support to subtypes¶
GNATfuzz now supports fuzzing Ada subtypes. For example:
package Foo is
type Bar is private;
subtype Baz is Bar;
procedure Qux (F : Bar; B : Baz);
private
type Bar is
record
I : Integer;
end record;
end Foo;
Beta script for automating project campaigns¶
A beta script titled “fuzz-everything.py” is provided to generate harnesses and run fuzzing campaigns for all fuzzable subprograms in a GPR project. The results of the campaigns in terms of coverage achieved and test cases found are provided in an outputted JSON file. The script is located in the <install path>/share/gnatfuzz/scripts/testing folder and detailed help can be found by running fuzz-everything.py –help..
GNATfuzz supports symbolic execution¶
GNATfuzz now includes a symbolic execution engine called “SymCC”. SymCC generates addition test cases that solve complex branch conditions to increase coverage and allow the fuzzer to explore and test more of the user code base.
New script to decode all testcases in a folder¶
All test cases within a results folder (queue, crashes, hangs etc) can now be quickly decoded using the decode_folder.py script. The script is located in the <install path>/share/gnatfuzz/scripts/testing folder and detailed help can be found by running decode_folder.py –help..
Support for public and private derived types¶
GNATfuzz now supports the fuzzing of public and private derived types. For example:
package Test is
type My_Record is record
I : Integer;
end record;
type My_Derived_Record is new My_Record;
procedure Foo (F : My_Derived_Record);
end Test;
Allow fuzzing of private subprograms¶
GNATfuzz now supports fuzzing Ada private subprograms. For example:
package System_Under_Test is
Dummy : constant Integer := 0;
private
procedure Subprogram_Under_Test (Input : Integer);
end System_Under_Test;
Derived record types with extensions¶
GNATfuzz now supports the fuzzing of derived record types with record extensions. For example:
package System_Under_Test is
type Foo is record
I : Integer;
end record;
subtype Bar is Foo;
subtype Qux is Bar;
procedure Subprogram_Under_Test (Input : Qux);
end System_Under_Test;
GS support for AFL modes Persist and Plain¶
The GNAT Studio gnatfuzz fuzz dialogue will now handle the AFL++ DEFER and DEFER_AND_PERSIST operating modes.
Optimizations¶
Inlining of witness subprograms¶
To monitor code execution, gnatcov inserts calls to “witness” subprograms before statements / decisions / conditions. Such calls can now be inlined when using optimization switches.
Improved test harness execution time¶
Verbose output from the generated test harness binary executable gnatfuzz-test_harness.afl_fuzz used during the fuzzing campaign has been moved to a separate executable gnatfuzz-test_harness.verbose resulting in an improved test harness execution time and an increase in the average test case executions per second. More executions per second equates to fuzzing campaigns satisfying their stopping criteria quicker.
New test harness build strategy¶
Compilation time of fuzzing campaigns has been significantly improved by only building the units within the closure of the subprogram under test, rather than the entire user project.
Improved gnatfuzz analyze logs¶
The gnatfuzz analyze command now logs all Libadalang diagnostics for the analyzed sources. Moreover, rather than terminating, it continues with the analysis using only the units that do not exhibit diagnostics.
Avoid secondary stack usage in instrumented code¶
The instrumentation process of gnatcov no longer introduces uses of the secondary stack for Ada source code. This means that a codebase that successfully compiles under the No_Secondary_Stack restriction will successfully compile after instrumentation for coverage under the same restriction.
GNAT Static Analysis Suite 25 Release Notes¶
We present here a few highlights of the new features in GNAT SAS 25. You can access the complete list in the GNAT SAS 25 feature file.
More precise analysis¶
Handle record initialization more precisely¶
Record initialization is now always handled precisely in Inspector analyses. Before this improvement, record initialization was treated imprecisely when the file containing the record declaration and the file where a record was initialized ended up in different partitions: the fields of the record were treated by Inspector as fully initialized. Now, the record initialization function is used in each partition. This improves precision when the analysis is run in fast mode or on a single file, but potentially also in deep mode.
Improve precision of use_for_of_loop rule¶
Prior to this change, this GNATcheck rule processed record component accesses very
imprecisely, basically considering that X.Component (I) and
Y.Component (I) were designating the same memory location no matter
the context, which could introduce false positives. This change improves
precision in that regard, by first checking whether the prefix of these
accesses represent the same memory location.
Improved analysis of arrays and pointers¶
The Inspector component of the GNATSAS static-analysis suite has been enhanced to provide a more precise, sound analysis of algorithms using array indexing and pointer dereferences. This new analysis is based on the notion of a “value history” that is maintained for each group of objects or object components that are mutually aliased, and tracks precisely all of the operations that might affect any member of a given aliasing group.
Handling uninitialized data¶
Detection of uninitialized out parameters by Infer¶
The Infer analysis backend is now able to detect an access to an uninitialized out parameter, even when it is of a record type. For an out parameter of an elementary type, Infer is also able to detect when it is not initialized at the end of a subprogram.
New analysis for initialization within Infer¶
We have introduced a new Infer analysis to detect that values are properly initialized before being accessed. Currently, this analysis operates on an intraprocedural level, meaning that it does not track uninitialized data across subprogram calls. Instead, it assumes that any data potentially modified by a subprogram call is initialized. This new analysis has a broader scope, as it explores all execution traces, resulting in more messages about potential initialization errors. It has the capability of detecting issues that were previously overlooked, offering more systematic error detection. Infer is now running both analyses; the previous one emits messages with a high ranking while the new one generates medium messages.
Improved tracking of uninit record fields by Infer¶
Infer is now able to track uninitialized record fields when copying records. As a result, it is able to better detect uses of uninitialized record fields.
Handling Ada constructs¶
Improved handling of ‘for of’ loops on arrays¶
The Infer backend for GNAT SAS now correctly understands the Ada “for of” iterator construct for arrays.
If_expressions support in redundant-Booleans rule¶
The GNATcheck ‘Redundant_Boolean_Expressions’ rule now flags if_expressions as violations when they contain a redundant Standard.Boolean literal.
User interface¶
No extra runtime needed¶
GNATcheck can now run with the GNAT SAS runtime and use it by default. This allows users to run GNATcheck without another installed Ada runtime.
Extend support for filtering with –show¶
Filtering with the “–show” switch is now supported for the GNAT Studio and HTML report formats. While the typical use case is that filtering is done directly by the user through filtering capabilities of GNAT Studio or WebUI (for the HTML report), adding this capability allows users to pre-filter the set of messages that will be available for GNAT Studio or WebUI. This can be useful in cases where there is a large number of messages or where the user wants to specifically view a subset of the messages without a strong need for dynamic filtering.
Displaying information about timelines¶
A new –list-timelines switch is added to all GNAT SAS commands. The switch provides a short list of the available timelines for the project specified with -P, followed with additional information about each timeline, such as the date of the last analysis run, the date of the baseline, the names of the corresponding SAM files, and the command-line and project switches that were used during the analysis.
Allow classic and LKQL rule files for the same run¶
You can now provide classic (“+R” style) and LKQL rule configuration files for the same GNATcheck run. This will combine the rules specified in each file.
Libadalang 25 Release Notes¶
We present here a few highlights of the new features in Libadalang 25. You can access the complete list in the Libadalang 25 feature file.
Libadalang API¶
Documentation for nodes now lists derived nodes¶
For all supported APIs, the documentation of all node types now includes the list of all directly derived nodes, with hyperlinks to the derived nodes.
A new kind of call supported by CallExpr.P_Kind¶
CallExpr.P_Kind can now be called on an entry indexing. P_Kind will return the Family_Index kind in that case.
New optional parameter for P_Get_Aspect property¶
The P_Get_Aspect property now takes a new optional parameter. By default, the P_Get_Aspect property checks for a given aspect (either specified by an aspect specification, a pragma, or a representation clause) on all the parts of a declaration, even the private ones. By setting Previous_Parts_Only to True, only previous parts (i.e. visible parts) are considered in order to comply with visibility rules.
New optional parameter for P_Has_Aspect property¶
The P_Has_Aspect property now takes an optional boolean parameter: Previous_Parts_Only. By default, the property will check for the given aspect on all parts of the declaration (even private ones). By setting Previous_Parts_Only to True, only previous parts are considered for aspect checking.
Usability¶
Correctness improvements in name resolution¶
Name and type resolution has been improved in multiple ways, including better support for corner cases of Ada’s semantics and name resolution inside generic instantiations has been heavily improved.
Emitting diagnostics for semantically invalid code¶
Libadalang’s name resolution can now emit diagnostics for some instances of semantically invalid Ada code, such as for type errors. This is a first step towards providing real-time diagnostics in our IDEs.
Reduced memory footprint for name resolution intensive applications¶
Libadalang’s memory footprint has been heavily reduced for applications that make heavy use of name resolution: cache mechanism for scopes is now able to detect entries that are less likely to be useful in order to evict them.
Ada 2022 and beyond¶
Libadalang fully supports Ada 2022 features supported by the GNAT compiler, and also implements new features part of the set of GNAT’s curated language extensions.
Added support for GNAT’s curated language extensions¶
Libadalang fully supports Ada sources containing use of features from the curated subset of GNAT’s language extensions, both for syntactic and semantic analysis:
Local declarations without blocks
Deep delta aggregates
Fixed lower bound for array types and subtypes
Prefixed-view notation for primitive calls on regular types
Expression defaults for generic formal functions
String interpolation
First_Controlling_Parameteraspect
You can see the full list of supported extensions in the GNAT reference manual here.
- orphan:
SPARK 25 Release Notes¶
We present here a few highlights of the new features in SPARK 25. You can access the complete list here.
Improved Support for Delta Aggregates and Container Aggregates¶
SPARK 25 has seen some improvements related to Delta Aggregates, which allow specifying a record object, expressing how it is different from an existing record, and the introduction of the Ada 2022 Aggregate aspects for containers. Let’s take a closer look.
Support for the GNAT Extension for Deep Delta Aggregates¶
As a GNAT-specific extension, subcomponents can be used as choices in delta
aggregates, in addition to top-level components, when specifying which
components have changed. As part of the experimental extensions in GNAT, this
is allowed by using the switch -gnatX0 or pragma
Extensions_Allowed(All). Both array and record subcomponents are supported,
as can we seen in the following example:
type Pair is record
Left, Right : Integer;
end record;
type Index is range 1 .. 10;
type Pairs is array (Index) of Pair;
procedure Zero_Left_Of_Pair_At_Index (P : in out Pairs; I : Index) with
Post => P = (P'Old with delta (I).Left => 0);
Support for the Ada 2022 Aggregate Aspect¶
The Aggregate aspect makes it possible to define aggregates for complex data structures. They are called container aggregates. This aspect is now supported in SPARK, but requires additional annotations to be handled by GNATprove. The container library provided in the SPARKlib has been annotated with this aspect, so it is now possible to use aggregates for formal and functional containers:
package Integer_Sets is new SPARK.Containers.Formal.Ordered_Sets (Integer);
S : Integer_Sets.Set := [1, 2, 3, 4, 12, 42];
package String_Lists is new
SPARK.Containers.Formal.Unbounded_Doubly_Linked_Lists (String);
L : String_Lists.List := ["foo", "bar", "foobar"];
package Int_To_String_Maps is new
SPARK.Containers.Functional.Maps (Integer, String);
M : Int_To_String_Maps.Map := [1 => "one", 2 => "two", 3 => "three"];
Program Specification¶
Annotation for Functions with Side Effects¶
In general, functions in SPARK shall have no side effects. This is essential to be able to call functions in assertions and contracts, as we don’t expect specifications to have an effect. This restriction has now been partially lifted. It is possible to declare functions with side effects in SPARK ((in-)out parameters and globals, non-termination, raising exceptions) if they are annotated with the aspect Side_Effects. A call to such a function can only occur in a list of statements, directly on the right-hand side of an assignment:
function Increment_And_Return (X : in out Integer) return Integer
with Side_Effects;
procedure Call is
X : Integer := 5;
Y : Integer;
begin
Y := Increment_And_Return (X);
-- The value of X is 6 here
end Call;
This feature facilitates writing bindings to C libraries, which often contain functions with side effects and meaningful return values.
Annotation for Mutable IN Parameters¶
In SPARK, parameters of mode IN and every object they designate are considered
to be preserved by subprogram calls unless the parameters are of an
access-to-variable type. In particular, IN parameters of a private type whose
full view is an access-to-variable type are considered as entirely immutable in
SPARK. However, it is rather common for existing Ada libraries to modify the
value designated by such parameters. The Mutable_In_Parameter annotation
instructs the SPARK toolset that such parameters should be considered as
potentially modified by a subprogram. This annotation is meant primarily to
interact with existing Ada libraries from SPARK code.
Annotation No_Bitwise_Operations on Modular Types¶
Mixing mathematical integers and bitvectors in some provers (cvc5 and z3)
sometimes leads to difficult proofs. The annotation No_Bitwise_Operations on
a modular type forces the use of mathematical integers in the prover for such a
type, instead of a bitvector. Note that a type with the annotation cannot be
used in bitwise operations (not, or, and, xor, shifts and rotates).
Annotation for Access-To-Subprogram Types Used for Handlers¶
A new annotation has been designed for access-to-subprogram types used for handlers - for example for interrupts. Unlike other access-to-subprogram types, such types can designate subprograms that access or update global synchronized data. The subprograms designated by access values of such types cannot be called in SPARK code.
New Contracts for SPARK-compatible Libraries¶
With SPARK 25 come new SPARK-compatibles libraries. Ada.Strings.Unbounded
have a set of complete contracts, following what was implemented in
Ada.Strings.Fixed and Ada.Strings.Bounded. A new SPARK-compatible
library of wrappers for Interfaces.C.Strings has been developed and is
available in SPARKlib, as SPARK.C.Constant_Strings. New Global contracts
have been added to the functions in the Ada.Generic_Elementary_Functions
package.
Tool Automation¶
New Prover Versions¶
The Z3 prover shipped with SPARK was updated to version 4.12.4. The cvc5 prover shipped with SPARK was updated to version 1.1.0.
Improved Performance for Large Projects¶
Several performance improvements have been implemented in SPARK 25. In particular, units that contain or depend on a large number of declarations are processed faster now. Similarly, units that refer to large records without actually referencing any of the fields are processed faster.
Unchecked_Conversion Precisely Checked in SPARK¶
When processing an instance of Ada.Unchecked_Conversion, SPARK was checking that the conversion makes sense: that it cannot generate an invalid value, that it always produces the same result given equal inputs, that the size of the source and target types are the same, etc. In addition to taking the size and alignment of types from the representation data generated by the compiler for the specified target, which was added in SPARK 24, GNATprove now also models precisely how bit patterns in the source type map to bit patterns in the target type, for most cases.
Managing Proof Context¶
By default, when verifying a part of a program, GNATprove chooses which
information is available for proof based on a liberal notion of visibility:
everything is visible except if it is declared in the body of another (possibly
nested) unit. It assumes values of global constants, postconditions of called
subprograms, bodies of expression functions… This behavior can be tuned either
globally or, in some cases, specifically for the analysis of a given unit,
using the dual annotations Hide_Info and Unhide_Info. For now, these
annotations cover 3 use cases:
To hide the private part of withed units.
To disclose the body of a local package.
To remove bodies of expression function locally on a case by case basis. Information hiding is decided at the level of an entity for which checks are generated. It cannot be refined in a smaller scope.
This new capability is described in the Additional Annotate Pragmas section of the User Guide.
Detection of Proof Cycles¶
In the past, SPARK had a documented tool limitation stating that undetected cycles in proof could result in an error message, as such cycles could cause unsoundness. SPARK 25 includes an automatic detection of such cycles caused by subtype predicates and type invariants, primitive equalities, Ownership and Iterable annotations among others.
Tool Interaction¶
Specify Subprogram by Name Instead of Location¶
The switch –limit-subp allows users to limit the analysis to a single
subprogram, specified by a file and line number. However, when the line number
changes, the command-line switch needs to be updated as well, which is
cumbersome. What is more, previously GNATprove did not do a good job of alerting
users that the argument to --limit-subp was incorrect after the change.
Two changes improve the situation in SPARK 25. First, SPARK now detects a
--limit-subp argument that doesn’t correspond to a subprogram. Second, a new
switch --limit-name has been introduced, which takes a subprogram name as an
argument. This variant is more robust with respect to changes of location of the
subprogram.
Parallel Invocations¶
Previously, GNATprove could not be invoked in parallel on the same project file. This is now possible, assuming that each invocation works with different object directories. This can be achieved using scenario variables.
Hard-to-Prove Checks Listed in the Log¶
The gnatprove.out file generated for a gnatprove run now contains
information about the 10 checks that were the hardest to prove, based on the
maximum time taken by a prover to prove a VC contributing to the check. Users
can look up this information to focus their efforts in reducing proving time and
increasing proof robustness.
Incompatible Changes¶
Removal of the CVC4 Prover¶
SPARK 24 still contained the now-obsolete CVC4 prover alongside its more modern variant, cvc5. In SPARK 25, CVC4 has now been removed.
Removal of Interactive Proof in GNAT Studio¶
The interactive proof feature, allowing users to apply tactics inside GNAT Studio to formulas in order to get them proved, has been removed from the SPARK product. This feature was made obsolete by improvements to autoactive proof through ghost code combined with the ability to use interactive proof inside the Coq proof assistant, also from GNAT Studio.
Command-Line Switches¶
The switch --proof-warnings now needs an argument on or off.
Previous usage of the switch should be replaced by --proof-warnings=on.
SPARK Library¶
The Modulus generic argument is now removed from the generic packages in
SPARK.Containers.Formal.Unbounded_Hashed_Maps and
SPARK.Containers.Formal.Unbounded_Hashed_Sets. This requires user code to
change, for example instead of writing:
package Sets is new SPARK.Containers.Formal.Unbounded_Hashed_Sets
(String, Ada.Strings.Hash);
S : Sets.Set (Default_Modulus (4));
one should now write simply:
S : Sets.Set;
IDE 25 Release Notes¶
We present here a few highlights of the new features in IDE products for the 25 release.
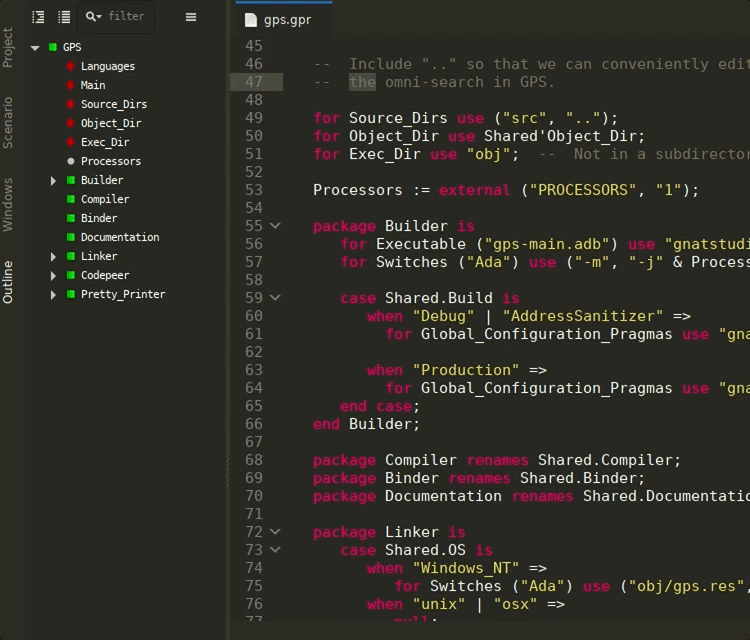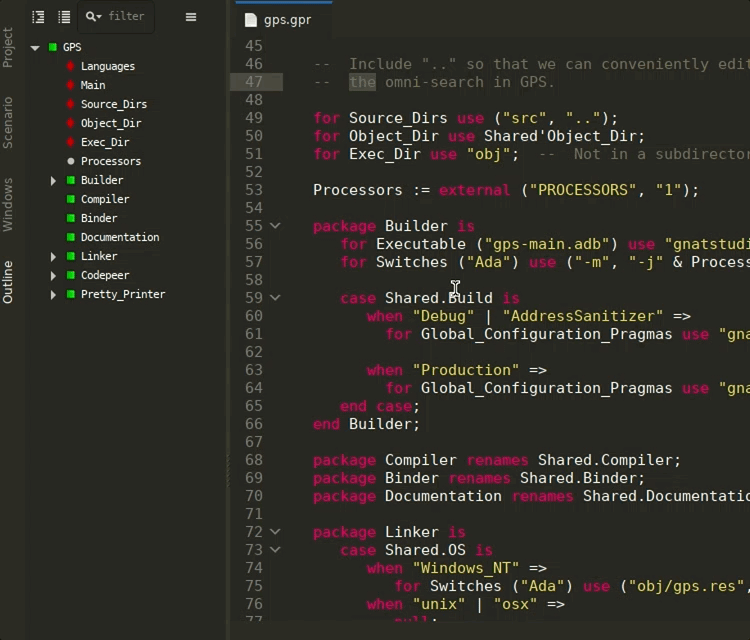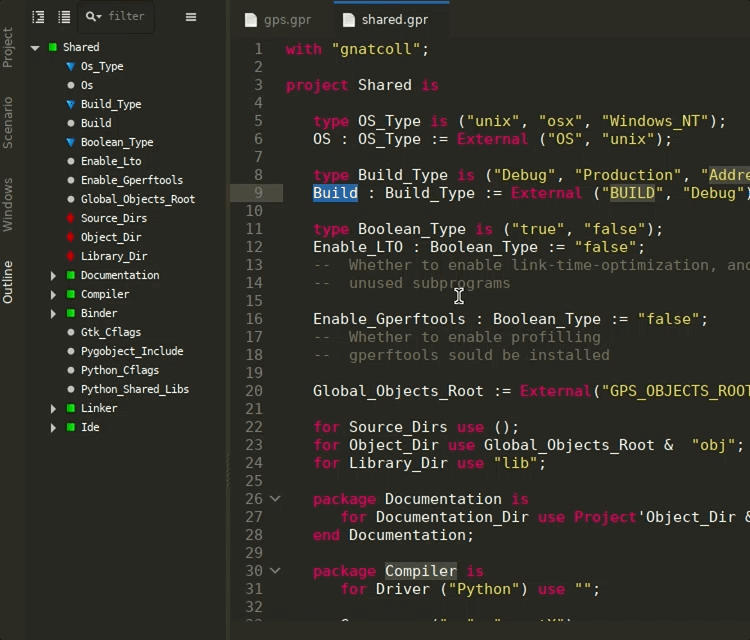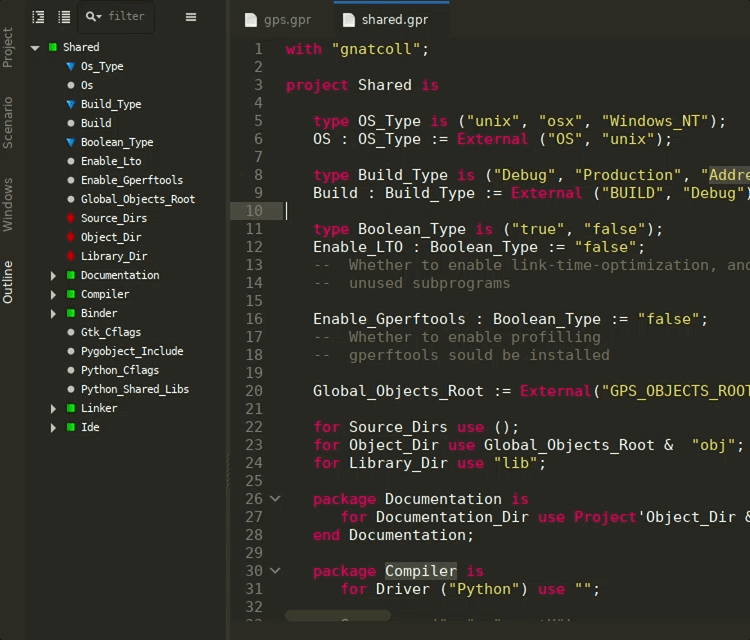
Ada Language Server for GPR files¶
A separate Ada Language Server instance is now launched specifically for GPR files, providing common IDE features such as completion, outline, tooltips, and navigation in GPR files via the LSP. This helps editing and understanding project files directly from GNAT Studio or Visual Studio Code.
SPARK in VS Code¶
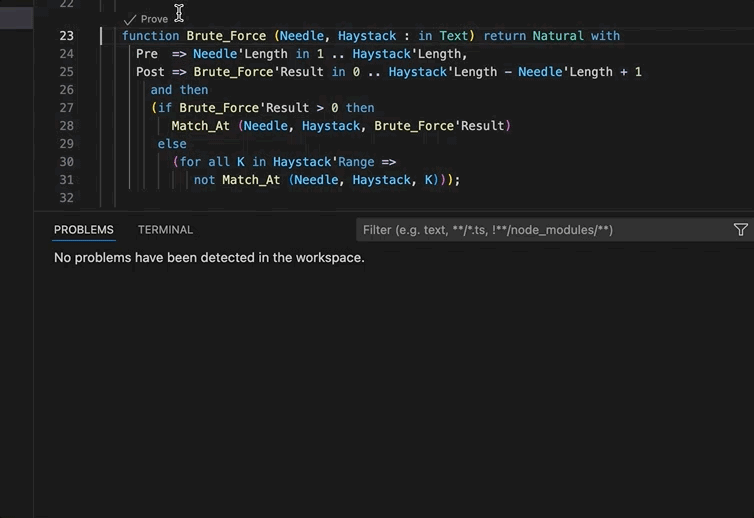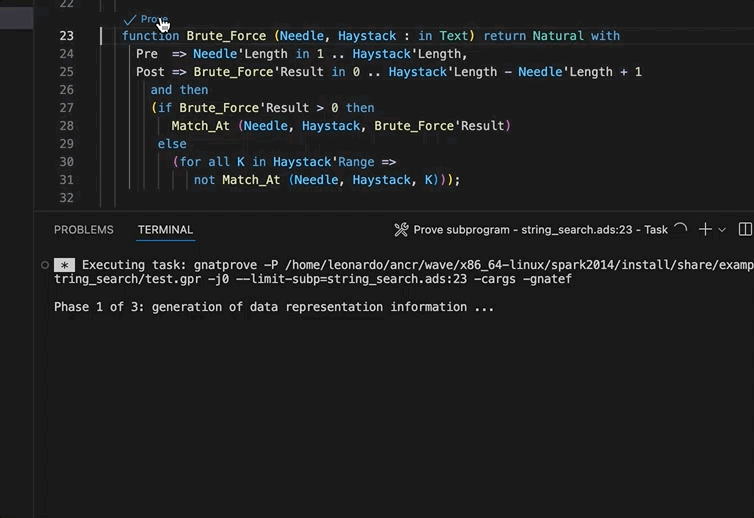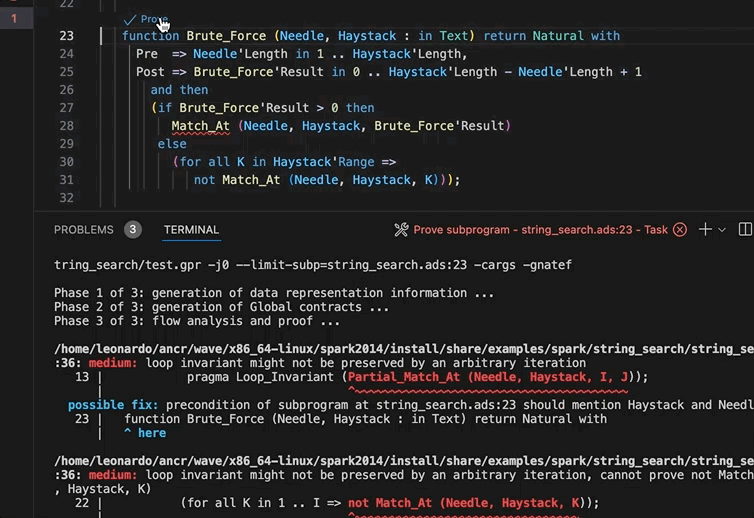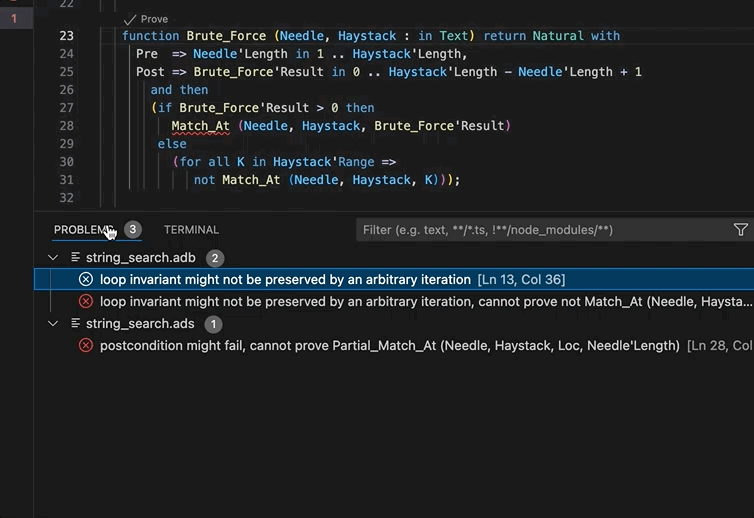
A few improvements have been made in the VS Code extension regarding SPARK integration. In particular predefined tasks for GNATprove have been added in order to prove a subprogram, a file or the whole project.
In addition, the extension will now display code lenses above subprograms and files to prove code directly from an opened editor.
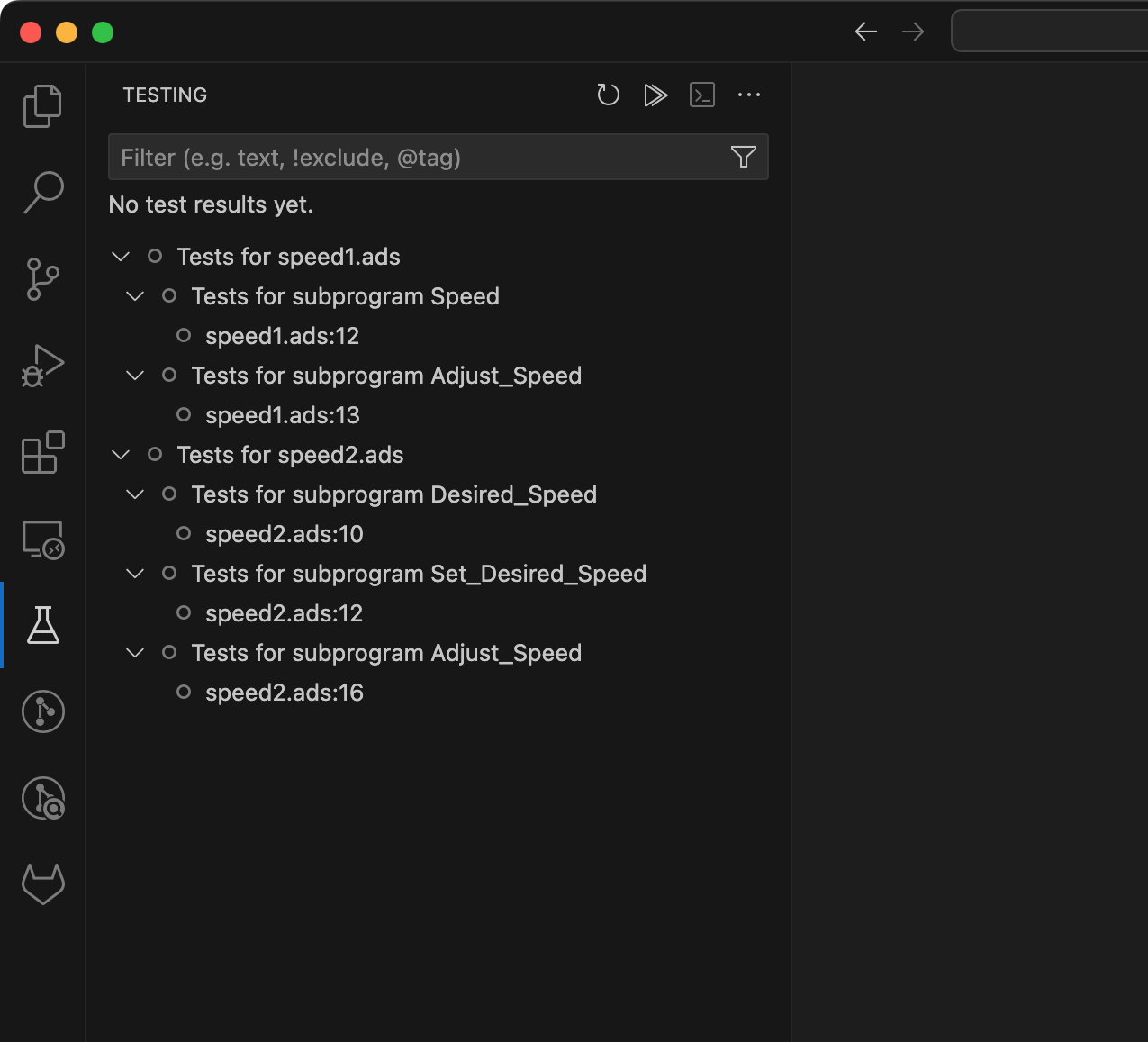
GNATtest in VS Code¶
An integration for GNATtest is now available through the Ada & SPARK VS Code extension, providing the following functionalities: predefined tasks to create/update test skeletons for the loaded project, and allowing you to run and visualize all your tests from the VS Code Testing view.
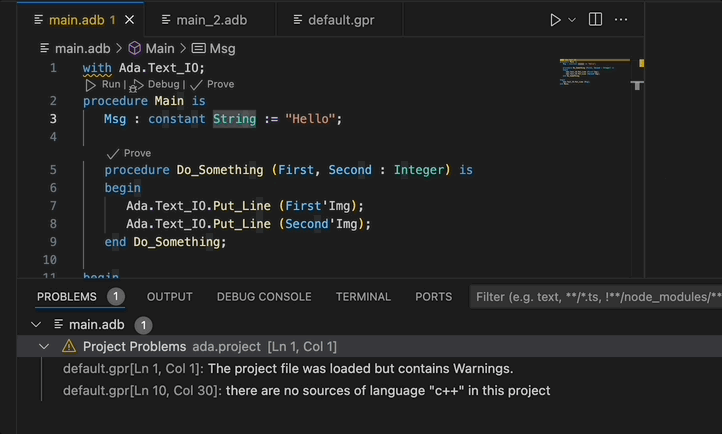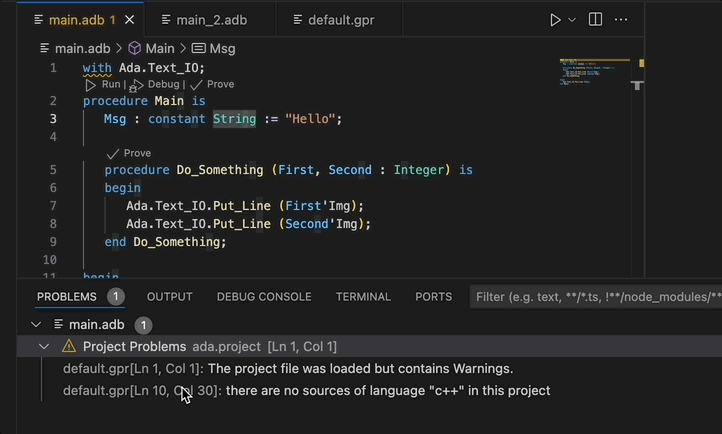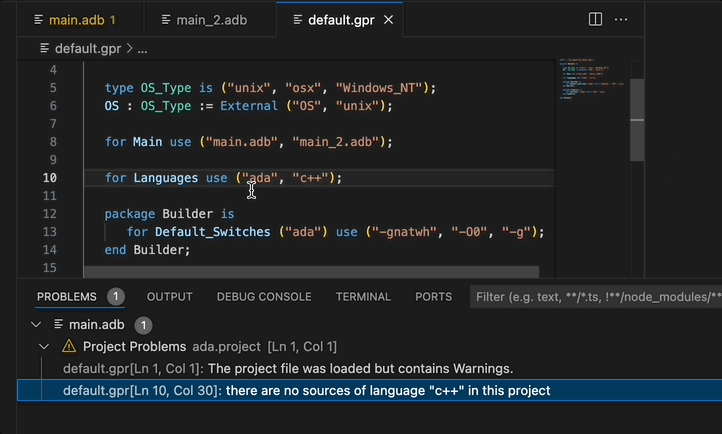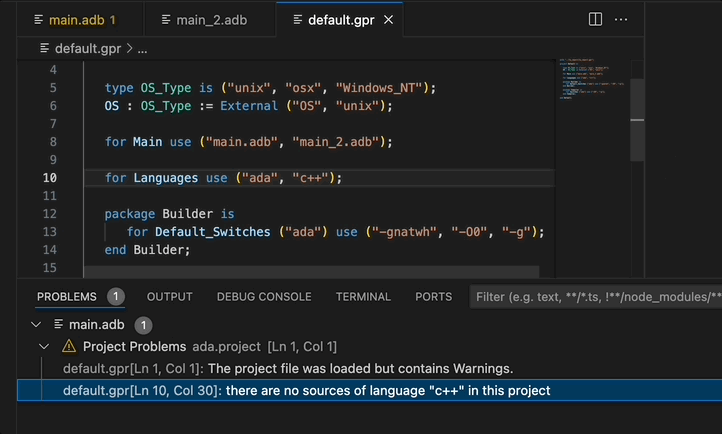
Project Diagnostics¶
The Ada Language Server now emits diagnostics for all the warnings and errors that were found while loading a project. These diagnostics are shown in GNAT Studio’s Locations view and VS Code’s Problems panel. These diagnostics can be disabled via a GNAT Studio preference (Enable project diagnostics in the Editor/Ada/Diagnostics preferences page) or, if you are using the Ada & SPARK VS Code extension, via the Ada: Project Diagnostics setting.
Formatting¶
The Ada Language Server now relies on a new formatter called GNATformat, replacing the old GNATpp formatter, which will be baselined soon.
This formatter is based on the Prettier formatter engine, which has been ported to Ada. The intent of GNATformat is to format valid Ada source code according to the coding style described in the GNAT Coding Style guide. The ability to customize the formatting style through configuration files will be progressively added in the next GNATformat versions.
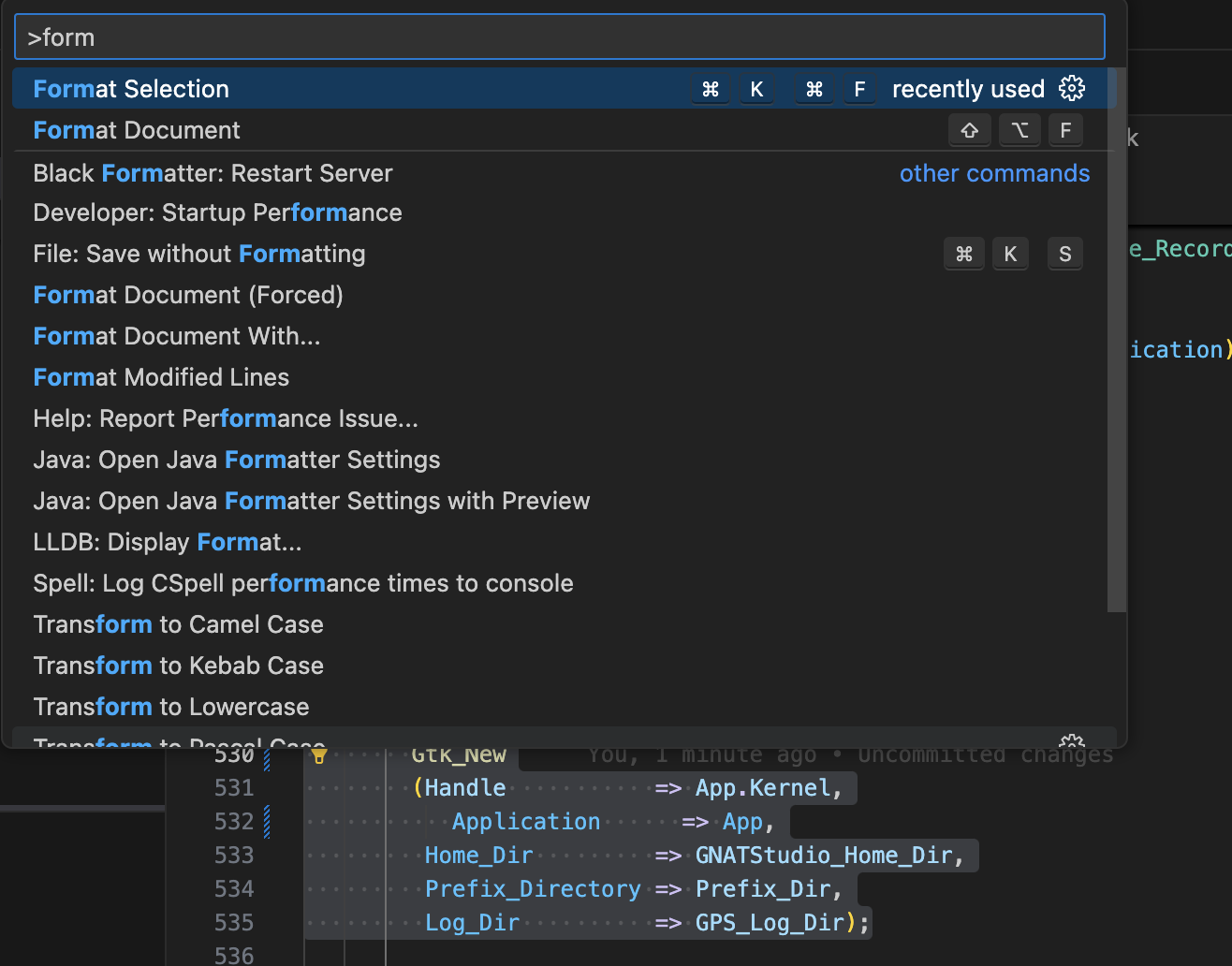
The VS Code extension for Ada & SPARK now uses GNATformat by default but users can fallback to GNATpp by disabling the Ada: Use GNATformat setting.
Regarding GNAT Studio, GNATformat is disabled by default until the complete transition to this new formatter, including preferences and formatting of whole projects. You can still experiment with it for file and range formatting based on the LSP by enabling the GPS.LSP.FORMATTING.ADA trace.
Editing and Completion¶
Tooltips for attributes, aspects and pragmas are now supported in the Ada Language Server.
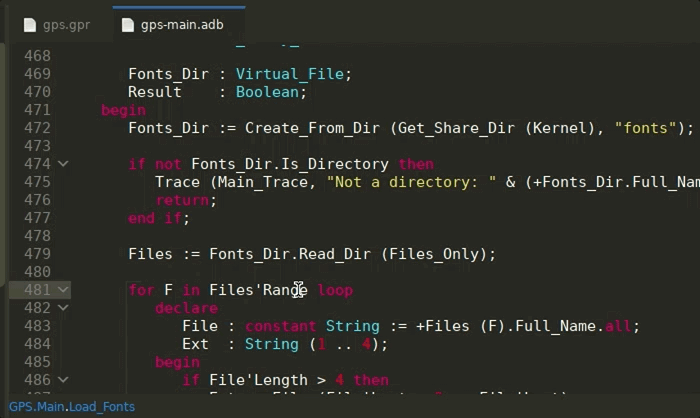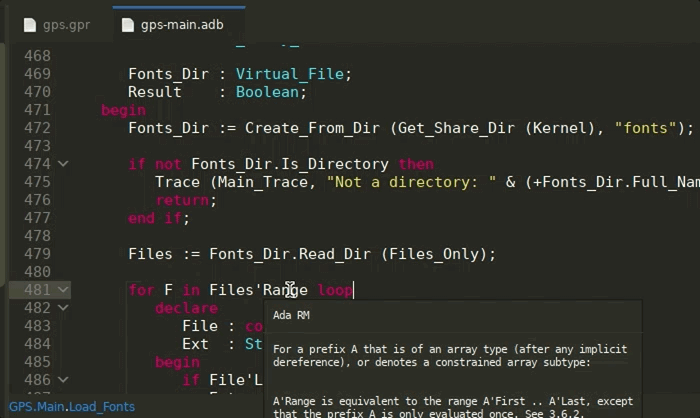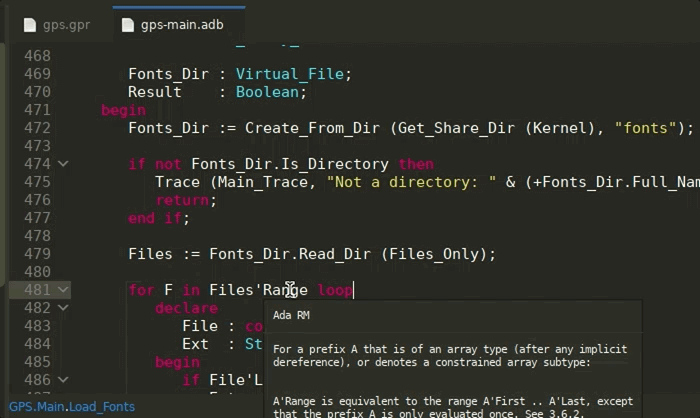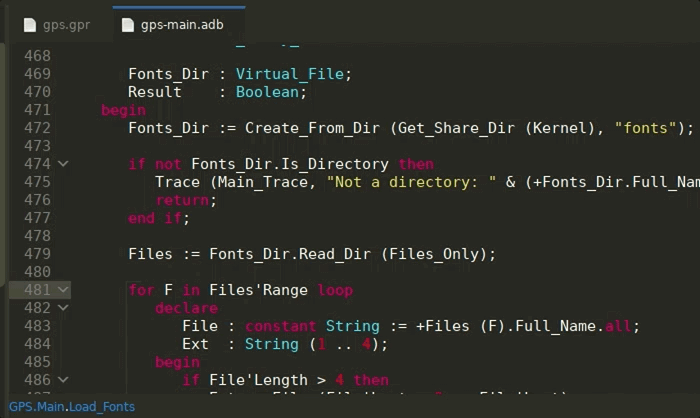
Selecting completion items that are not visible in the current scope will now automatically trigger the Ada Language Server’s auto-import command, adding the missing with clauses and prefixing with a qualifier if needed. This can be disabled via the Insert with clauses preference, in the Editor/Ada preferences page.
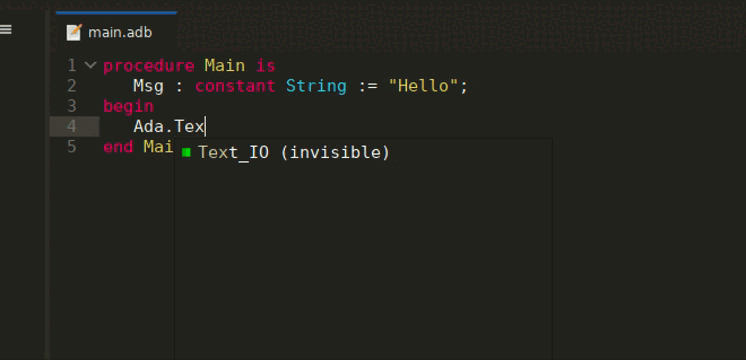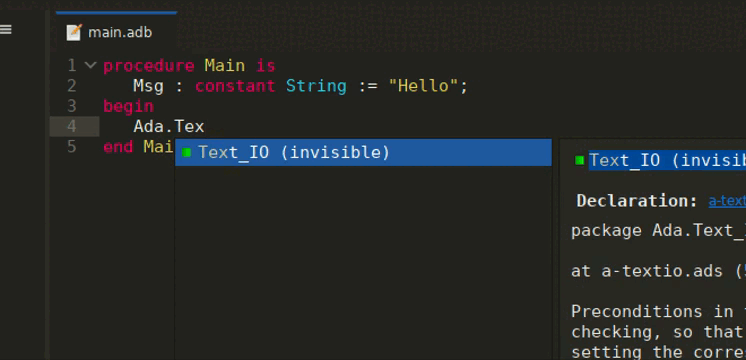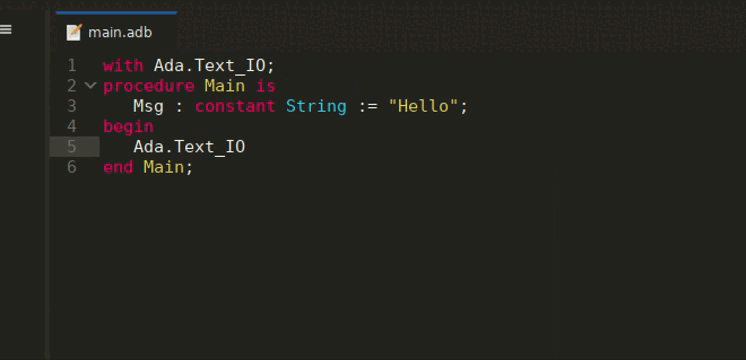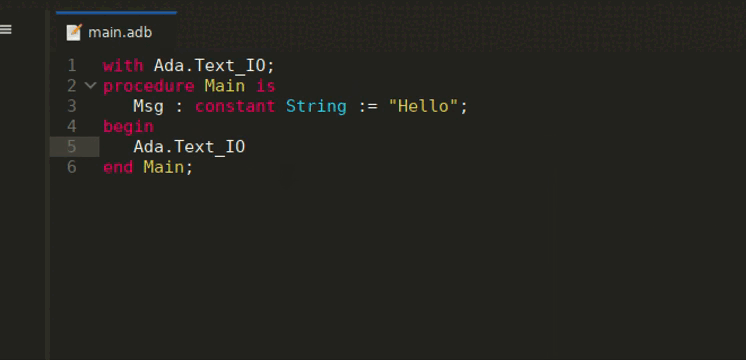
LSP-based Semantic Highlighting is now available in GNAT Studio. This allows to highlight differently more fine-grained semantic categories, for instance to distinguish constants from writable variables. You can enable this feature via the LSP Semantic Highlighting preference in the LSP preferences page. The colors for each category can then be customized through the Semantic section of the Editor/Fonts & Colors preferences page.

Debugging¶
GNAT Studio now supports Microsoft’s Debug Adapter Protocol to debug Ada code.
The idea behind the Debug Adapter Protocol is to standardize an abstract protocol for how a development tool communicates with concrete debuggers, similarly to what the LSP does for languages. This makes interactions with underlying debuggers faster and more reliable in the long-run.
The implementation has some limitations for now, in particular regarding remote debugging: thus it needs to activated manually by enabling the GPS.DEBUGGING.DAP_MODULE trace. You will also need a recent GDB version (25 release at least) to benefit from the best user experience.
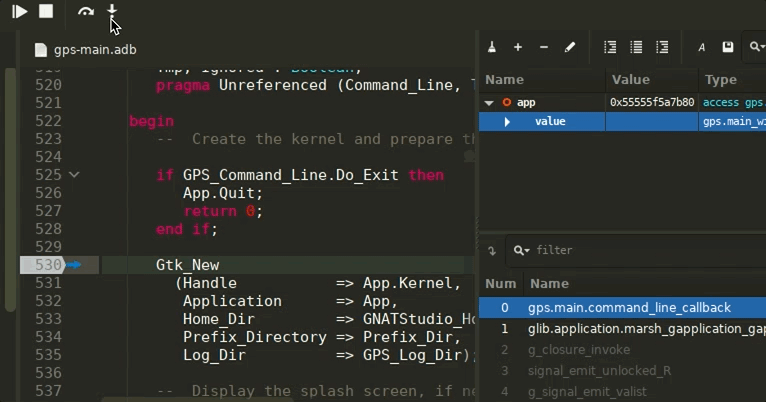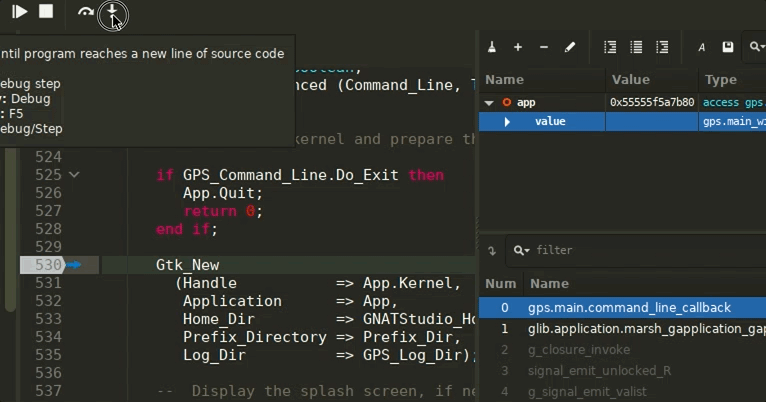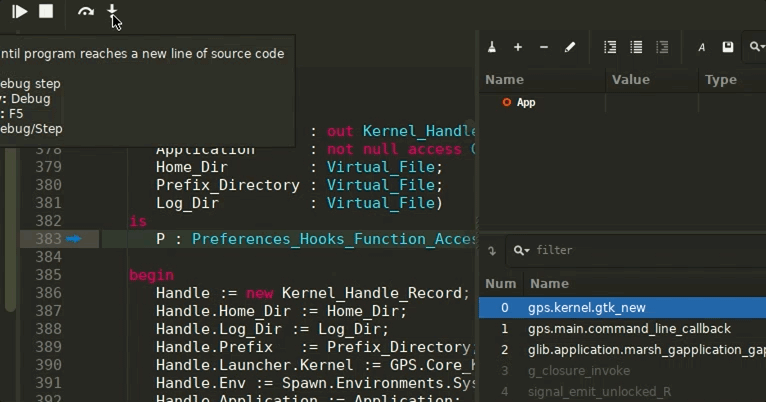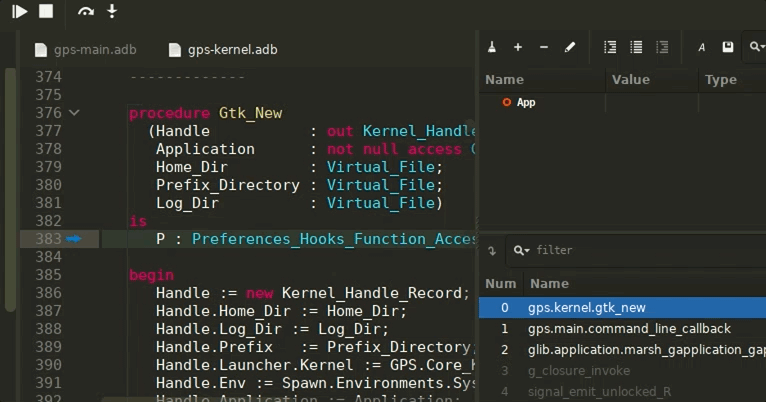
Using the DAP module comes with a few UX improvements: the Call Stack view now will automatically select the first reachable frame, opening its source location, and will gray out the frames that are not accessible (i.e: when the source path does not exist on disk).
Alire integration¶
When opening a .gpr file belonging to an Alire project (i.e: when the project’s directory contains an alire.toml file), GNAT Studio is now able to correctly load it by running the alr printenv command to set up the needed environment, displaying a message in the Locations view once it’s setup.
The default build targets to build and clean projects are also replaced by the respective Alire commands
(alr build and alr clean).
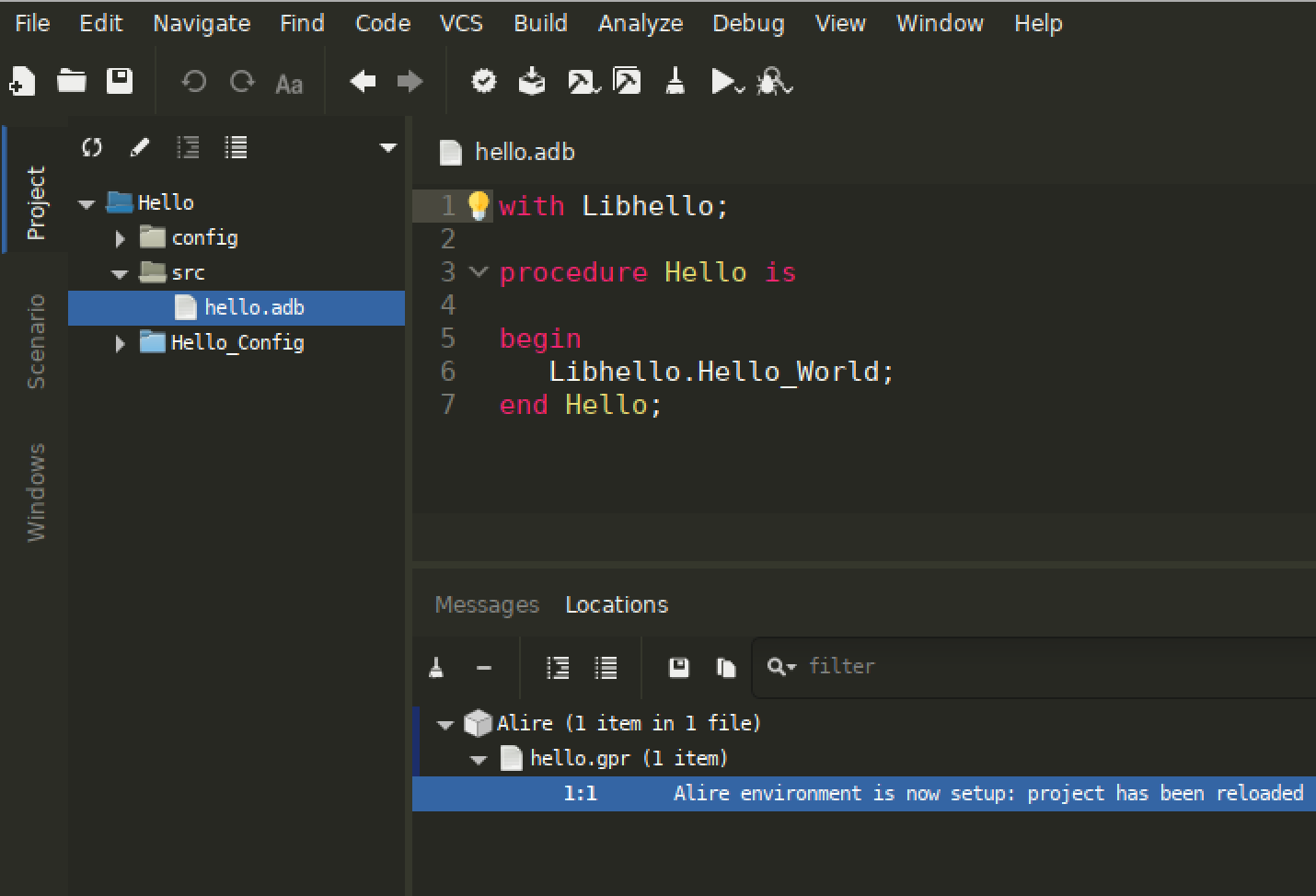
On the VS Code extension’s side, a few bugs have been fixed regarding the Alire integration.
In particular the Ada Language Server for GPR files is now also able to load Alire projects.
Note that all the predefined tasks provided by the Ada & SPARK VS Code extension will run through Alire:
for instance, the ada: Build current project task will run the alr build command and tasks that
spawn external tools will be prefixed by alr exec.